为什么并发编程会产生 bug
本文结构
为什么需要并发编程
我们都知道计算机的核心组成 CPU,内存,I/O 设备的运行速度差异是很大的,它们间的速度是 CPU >> 内存 >> I/O,CPU 和内存的速度差异就如同天上一天和地上一年的差别。而内存和 I/O 设备的速度差异就更大了,相当于天上一天与地上十年的区别。
而程序里大部分语句都要访问内存和 I/O,所以一段程序执行的性能是取决于最慢的那部分的执行速度——即读写 I/O 设备。 所以,如何合理的平衡这三者的速度差异来使程序运行的最快呢? 这就需要从计算机体系结构,操作系统,编译程序这些方面进行优化了。目前计算机科学界的大佬们对在这些方面做出的优化主要有以下几点:
1、 CPU 增加了缓存,用来缓存常用的内存数据或地址,以均衡与内存的速度差异;
2、操作系统增加了进程、线程,用来对 CPU 进行分时复用,进而均衡 CPU 与 I/O 设备的速度差异;
3、编译程序优化指定执行次序,使得缓存能够得到更加合理的利用。
这几点的优化在一定程度上大大提升了程序的运行速度,但是相应的也产生了并发程序的一些问题,也就是并发编程可能会出现的 bug。
为什么会产生 bug
首先,我们需要定义一下这个 bug 是什么样的 bug。
并发编程,所引起的问题,其本质 bug 就是对某个资源的操作没有
原因一:CPU 缓存带来可见性问题
在单核的 CPU 中,所有的线程都是在一颗 CPU 上执行,因为所有线程都是操作同一块缓存和内存,所以不同线程对缓存的写,是互相透明的。

但是在多核时代,每个 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就不容易保证了。当多个线程在不同的 CPU 上执行时,这些线程操作的是不同 CPU 的缓存,如下图:
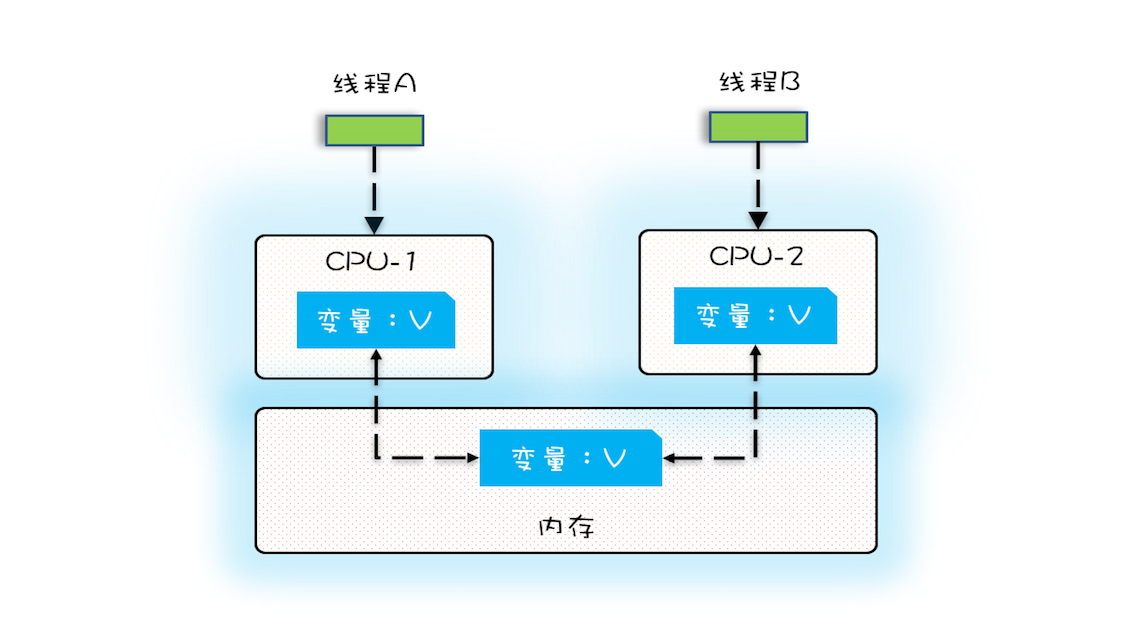
线程 A 操作的是 CPU-1 上缓存,而线程 B 操作的是 CPU-2 上的缓存,这个时候,线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。举个例子,假设变量 V 初始值为 0,线程 A 从内存读取变量 V 到 CPU 中并缓存起来,随后线程 A 对变量 V + 1 并更新缓存,而此时,线程 B 也从 内存读取变量 V,然后也开始执行 +1 操作并进行更新缓存;这样当线程 A 把变量 V 的值从缓存写入到内存里后,变量 V 的值为 1,而当线程 B 也将变量 V 写入到缓存时,变量 V 的值也是 1,最终就是变量 V 虽然被两个线程分别执行了两次 +1 操作,但是其最终的值却是 1,而不是我们期望的正确值 2。这就是可见性引起的问题。
原因二:线程切换带来的原子性问题
我们都知道 Unix 采用分时复用的方式,即通过对线程进行调度切换来提高 CPU 的利用率
由于我们现在编程基本都是使用高级语言,高级语言里的一条语句往往需要多条 CPU 指令完成。例如 count += 1, 至少需要三条 CPU 指令。
指令 1: 将变量 count 从内存加载到 CPU 的寄存器;
指令 2: 在寄存器中执行 +1 操作
指令 3: 将结果写入缓存
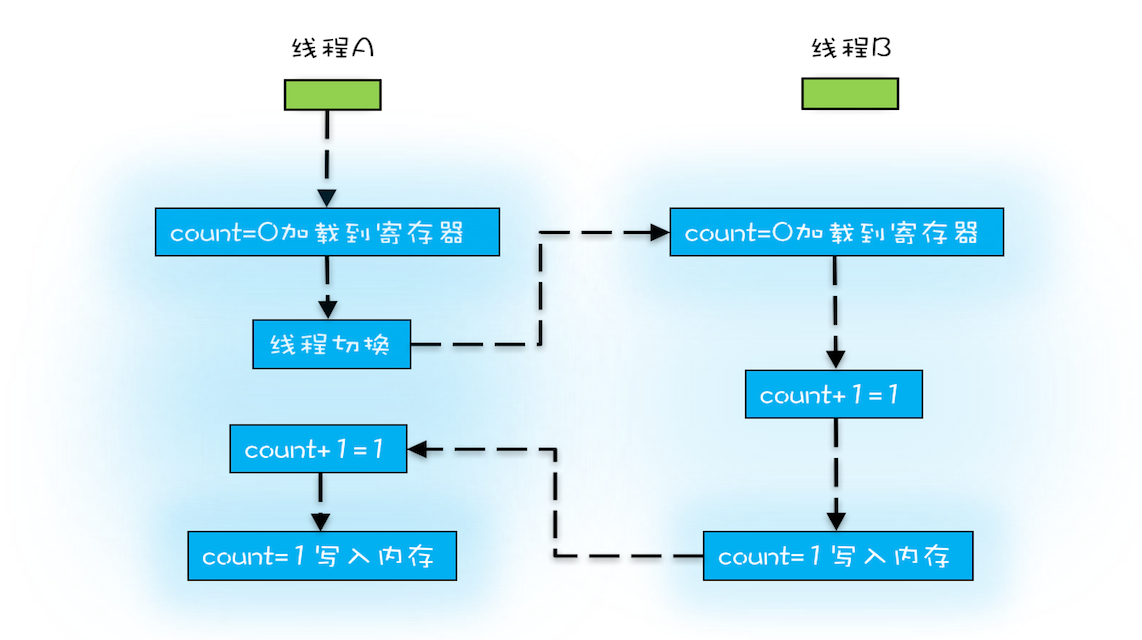
而操作系统在线程切换时,可以发送在任何一条 CPU 指令 执行完,而高级语言里的一条语句。对于上面的三条指令来说,假设 count 为 0, 如果线程 A 在指令 1 执行完后做线程切换,线程 B 开始执行三条指令后,即将 count 的值 +1 并写入了缓存了,这时再切换回线程 A,由于线程 A 在前面已经执行了指令 1,线程 A 里的 count 值是 0,此时再去执行指令 2 和指令 3,最后线程 A 执行完后,count 的值依然为 1。即 count 变量分别被两个线程获取并进行了 +1 的操作,但是最终的结果是 1 而不是我们所期望的正确值 2。这就是线程切换引起的问题。
上述过程示意图如下:
原因三:编译优化带来的有序性问题
编译优化是指当我们的程序进行编译后,编译器为了优化性能,有时候会改变程序中语句的先后顺序。例如 “a = 1; b = 2;” 编译器优化后可能变成“b = 2, a = 1”。
在 Java 领域一个经典的案例就是利用双重检查创建单例对象。在实现单例的时候,首先判断 instance 是不是为空,如果为空进入同步代码块初始化 instance,否而直接返回 instance。初始化 instance 时再次判断 instance 是否为空,避免了在进入同步代码块这段时间有线程抢先一步完成了 instance 初始化。代码如下:
1 |
|
这种单例的实现方式,看似在提高效率的同时,做到了天衣无缝。其实不然,因为 instance = new Singleton (); 这一行代码会被编译为三条指令,正常指令顺序如下:
1、为 instance 分配一块内存 A
2、在分配的内存 A 上初始化 instance 实例
3、把内存 A 的地址赋值给 instance 变量
而编译器优化后可能会变成:
1、为 instance 分配一块内存 A
2、把内存 A 的地址赋值给 instance 变量
3、在分配的内存 A 上初始化 instance 实例
上面的顺序调换在单线程环境下是没有问题的,但是在多线程的情况下,假如线程 A 正在初始化 instance,此时执行完第 2 步,正在执行第三步。而线程 B 执行到 if (instance == null) 的判断,那么线程 B 就会直接得到未初始化好的 instance,而此时线程 B 使用此 instance 显然是有问题的。
要解决本例的有序性问题很简单,我们只需要为 instance 声明时增加 volatile 关键字,volatile 修饰的变量是会保证读操作一定能读到写完的值。
总结
要写好并发程序,首先要知道并发程序的问题在哪,是因为什么引起的。并发程序问题的产生主要是由可见性,原子性,有序性这三方面引起。
此外,上面所提到的缓存,线程,编译优化的目的与我们写并发程序的目的是相同的,都是提高程序性能。但是,从这里我们可以看到,技术在解决一个问题的时候,很难有完美的解决方案,往往是解决了问题的同时也会带来另外的问题。所以在采用一项新技术的同时,一定要清楚它能解决什么问题,可能带来什么问题,以及如何进行规避。